Shakespeare ist tot! Lassen Sie die Intelligenz des maschinellen Lernens in Ihren Text einfließen.

Wohin dürfen wir das PDF senden?
Ein Beispiel für prädiktive Textbewertung und Stimmungsanalyse mit maschinellem Lernen aus erster Hand.
Wir sind immer auf der Suche nach einem Weg, das maschinelle Lernen in ERP-Systeme zu integrieren. Unternehmen können ein Predictive Scoring mit maschinellem Lernen (EN: Machine Learning) anwenden, um Vertriebsleads zu priorisieren, Cross-Selling-Möglichkeiten zu entdecken und Texte zu klassifizieren.
Um die Bemühungen unseres B2B-Marketingteams zu unterstützen, haben wir Zeit und Ressourcen investiert und ein maschinelles Bewertungssystem für unsere Blog-Inhalte entwickelt.
Wir glauben, dass unsere Erfahrung damit für andere B2B-Marketing-Teams wertvoll sein kann.
Stellen Sie sich vor, Sie arbeiten in einem Content-Marketing-Team und möchten vorhersagen, ob ein neuer Artikel den Traffic auf Ihrer Unternehmensseite steigern und die Konversion erhöhen wird. Sie besitzen Hunderte von Artikeln aus der Vergangenheit, von denen bekannt ist, dass sie den Web-Traffic angetrieben und Ihnen wertvolle Verkaufs-Leads gebracht haben.
Sie können mit Ihrem eigenen Webanalysetool (z.B. Google Analytics) messen, welche Artikel mehr Traffic und die meisten Leads bringen. Danach werden Sie versuchen herauszufinden, welche Merkmale, Schlüsselwörter und Absätze Ihren Erfolg gebracht haben.
Wir haben unser Modell mit Texten aus unserem Blog trainiert. Sie können dieses Beispiel allerdings auch auf andere Text-Sentiment-Analysen anwenden, wie beispielsweise Social Media, Vertriebsberichte und Marketing-E-Mails. Wir haben AutoML von Google verwendet, wobei es Ihnen natürlich freisteht einen anderen Anbieter für maschinelles Lernen zu verwenden.
Wir haben unser Modell mit Texten aus unserem Blog trainiert.
Lassen Sie uns gemeinsam einige grundlegende Konzepte über maschinelles Lernen, Klassifizierung von Texten und Gefühlen besprechen und dann die Ergebnisse unseres Beispiels präsentieren.
Warum ist Machine Learning (ML) das richtige Werkzeug für Textanalysen und Lead-Scoring?
Klassische Programmierung, wie z.B. Standard Lead Scoring, erfordert, dass der Softwareentwickler dem Computer Schritt-für-Schritt-Anweisungen und Regeln vorgibt. Diese Methodik funktioniert bei relativ einfachen Fällen gut. Nehmen jedoch die Komplexität und die Variationen unstrukturierter Daten zu, wie z.B. in einem Text, weiß man nicht mehr wo man anfangen soll. Glücklicherweise kann die maschinelle Lernsoftware aus den Daten lernen und dieses Problem effizient lösen.
Textanalyse und Lead-Scoring sind aus Sicht der Datenstruktur verschieden. Das Erste arbeitet mit unstrukturierten Daten, das Zweite mit (meist) strukturierten Daten. Es gibt jedoch, aus Sicht des maschinellen Lernens, einige Gemeinsamkeiten.
Für beide Methoden der prädiktiven Analytik wird ein Algorithmus, in der Regel auf Grundlage eines „random forest“-Prädikators, Elemente auf Grund von vormarkierten Ziel-Elementen bewerten oder klassifizieren. Durch diese Anwendung, die wir hier beschreiben, haben wir beispielsweise unsere Blogbeiträge durch eine Stimmungsanalyse (oder auch „Sentiment-Score“) vorselektiert.
Wie haben wir unseren Machine-Learning-Textprädikator aufgebaut, welche Tools und Daten haben wir verwendet?
Beim maschinellen Lernen werden Daten verwendet, um Algorithmen zu trainieren, sodass sie das gewünschte Ergebnis erzielen. Mit Google Analytics haben wir fast 200 Artikel aus unserem Blog in vier Kategorien oder auch „Sentiment“ vorklassifiziert: Von 0 bis 3 – je höher die Kategorie, desto besser der Artikel. Wir haben „besser“ definiert, indem wir drei Variablen betrachtet haben: Anzahl der organischen Leser, Bounce-Rate und Anteil der Besucher, die eine Kontaktanfrage gestellt haben. Diese Kategorien haben wir gewichtet.
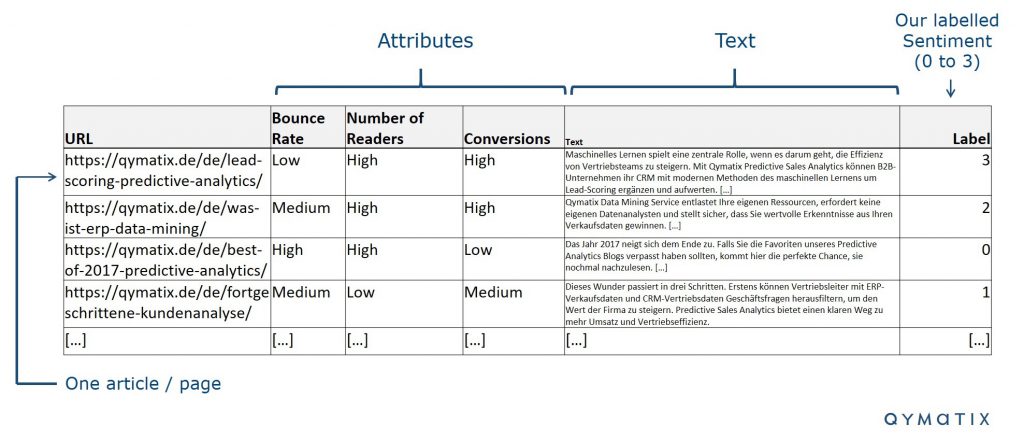
Der erste Schritt ist die Beschaffung der Daten. Die billigste und zuverlässigste Datenquelle ist natürlich unser Blog selbst. Die Verwendung der Daten, die ein Unternehmen bereits besitzt, ist der sinnvollste Ansatzpunkt in fast jedem maschinellen Lernprojekt.
Die Datenaufbereitung ist der zweite und vielleicht kritischste Aspekt eines jeden maschinellen Lernprojekts. Um das Modell zu trainieren, müssen wir die markierten Daten zusammen mit dem Sentiment oder der Bewertung, welche wir durch das Modell erfahren wollen, zur Verfügung stellen.
Im obigen Bild haben wir einen Auszug aus der von uns verwendeten Datenbank dargestellt. Dort sind alle URLs aus unserem Blog aufgelistet. Über den URL-Link zieht sich die Datenbank den dazugehörigen Text und alle Beiträge wurden von 0-1 gekennzeichnet.
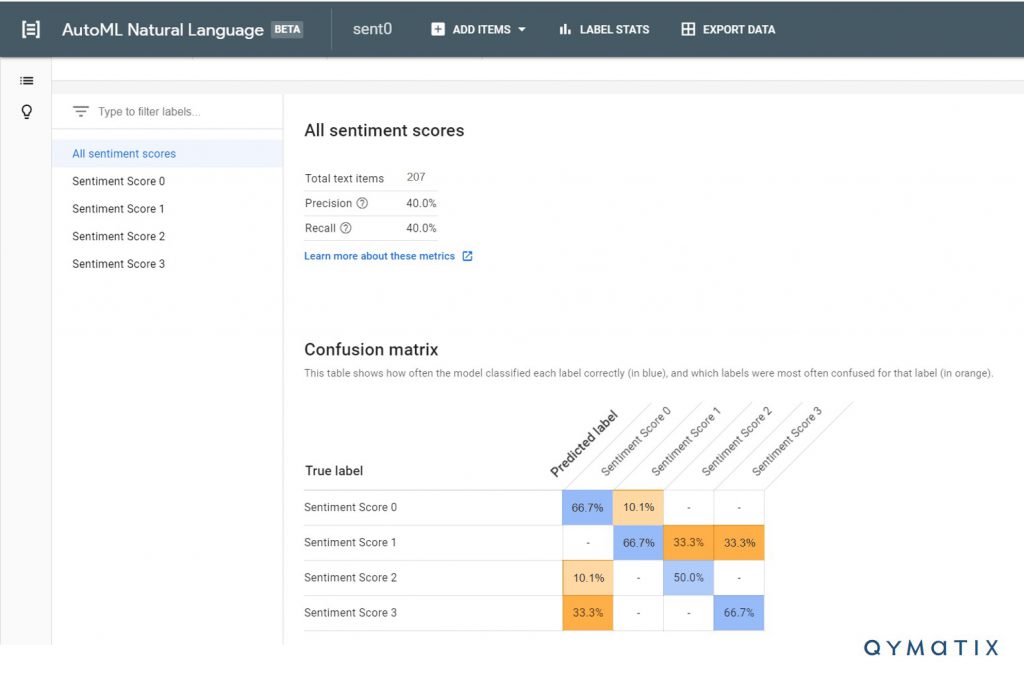
Jetzt kommt die Magie. Wie kann man unstrukturierte Daten (Text aus den Artikeln) verwenden, um vorherzusagen, wie erfolgreich der nächste Artikel sein wird? Unter Verwendung von überwachtem maschinellem Lernen trainierten wir ein Modell, um die Muster und Inhalte zu erkennen, die wir als Sentiment 3 (unsere erfolgreichsten Artikel) bezeichneten. Es sollte eine gleichmäßige Verteilung der Kategorien geben, und Sie benötigen eine Mindestanzahl von Elementen in jeder Einheit, sagen wir zehn Artikel pro Sentiment. Um etwa gleich viele Trainingsbeispiele für jede Kategorie zu erfassen, haben wir den 200er Eintrag in fast vier gleichmäßig verteilte Kategorien (jeweils rund 50) aufgeteilt. Unten sehen Sie die Kosten-Nutzen-Matrix, die sich aus unserem Training ergibt.
Was haben wir aus dieser Anwendung des maschinellen Lernens gelernt und wofür können wir es nutzen?
Wir haben drei Lektionen gelernt. Erstens hatten wir mehr Daten, als wir dachten. Zweitens, dass man mit dem richtigen Werkzeug die vorliegenden Daten nutzen kann, um bessere Entscheidungen zu unterstützen. Drittens macht maschinelles Lernen für Marketing und Text-Sentiment-Analyse Spaß.
Kommen wir nun zu seiner Anwendung. Wir können unserem neu geschulten Modell des maschinellen Lernens grundsätzlich einen Text „geben“ und das Modell sagt uns wie erfolgreich dieser Text sein könnte. Es prophezeit also den Erfolg des neuen Texts durch eine Einordnung in Sentiment 0 bis 3. Wir fütterten das Modell mit Texten aus Publikumszeitschriften und erhielten eine Auswahlliste von Artikeln und Themen, die uns bessere Ergebnisse bringen könnten. Unten sehen Sie ein Beispiel dafür, wie es funktioniert.
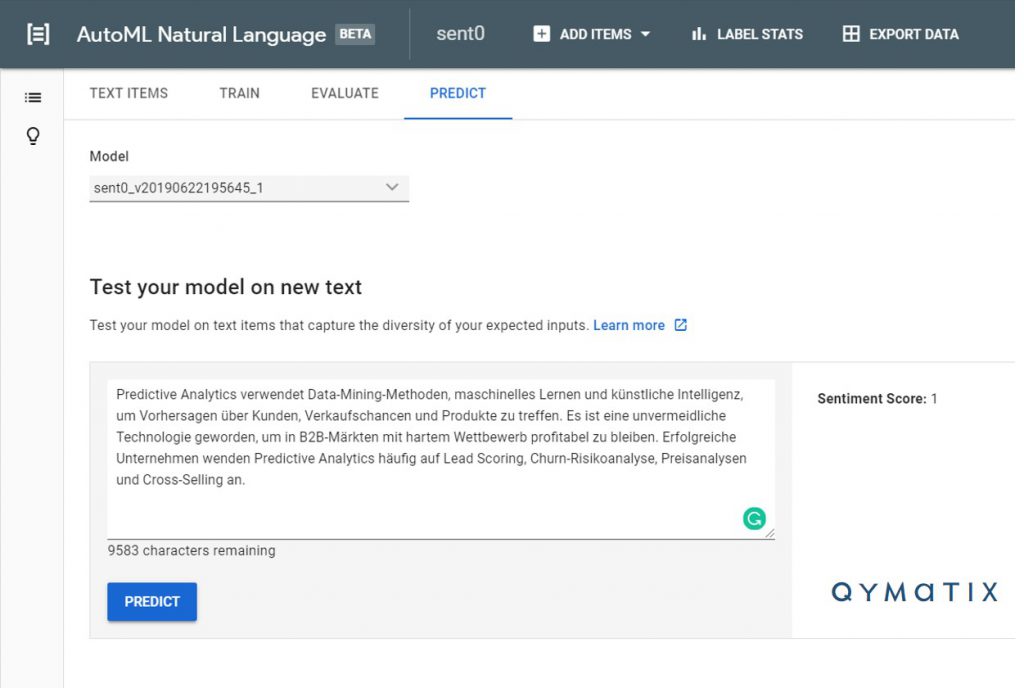
Verwenden wir dieses Modell, um die Texte in unseren Artikeln bequem automatisch schreiben zu lassen? Natürlich nicht. Wir verwenden es nur, um unsere Entscheidungen über Inhalte und Keywords zu unterstützen.
Wir wiederholen jetzt kurz ein paar Schritte, wie Sie mit der Predictive Analytics beginnen können:
>> Bestimmen Sie Ihr Unternehmensziel
>> Verwenden Sie die Daten, die Ihrem Ziel am nächsten kommen
>> Auswählen und Trainieren eines Modells
>> Wenden Sie die Erkenntnisse an, um Ihre Entscheidungen zu verbessern
Wir sind uns sicher, dass diese Schritte sehr nützlich für Unternehmen sind, die mit der prädiktiven Analyse mittels maschinellen Lernens beginnen wollen.
BERECHNEN SIE JETZT DEN ROI VON QYMATIX PREDICTIVE SALES SOFTWARE
Beispiel für prädiktive Textbewertung und Sentiment-Analysen mit maschinellem Lernen – Fazit.
Stellen Sie sich vor, Sie sind ein Marketingmanager und Sie möchten Ihre Texte so verfassen, dass sie das Engagement und neue Leads fördern. Alternativ können Sie sich vorstellen, dass Sie ein Vertriebsleiter sind, der Hunderte von E-Mails pro Woche schreibt und wissen möchte, welche der Mails einen höheren Rücklauf generieren. Erkenntnisse aus riesigen Mengen unstrukturierter Daten, wie z.B. Texte, zu gewinnen, ist für einen Menschen eine unmögliche Herausforderung.
Machine Learning ist das richtige Werkzeug für die Textanalyse. Wir haben in diesem Beispiel einen Text-Sentiment-Algorithmus trainiert, um die Artikel zu klassifizieren, die ein höheres Engagement in unserem Blog bewirken sollen. Machine Learning, ein Beispiel für schwache künstliche Intelligenz, kann auch für weitere Anwendungen im B2B-Vertrieb und -Marketing genutzt werden, wie Lead-Scoring, Abwanderungen verhindern sowie Präventions- und Preisanalysen.
Für unseren maschinell lernenden Textprädikator haben wir AutoML von Google verwendet, es sind jedoch auch andere Tools verfügbar. Erstens haben wir fast 200 Inhalte, Seiten und Beiträge vorab gekennzeichnet – basierend auf dem Grad des Engagements. Anschließend trainierten wir das Modell und überprüften seine Leistung anhand einer Kosten-Nutzen-Matrix. Wir haben schließlich unser Modell verwendet, um neue Textteile vorherzusagen.
Wir haben aus dieser Anwendung des maschinellen Lernens gelernt, dass es einfache Möglichkeiten gibt, mit der prädiktiven Analytik zu beginnen – wenn man weiß wie. Wir haben die Daten, die wir bereits hatten, verwendet, und wir nutzen diese Erkenntnisse, um unsere zukünftigen Artikel zu verbessern.
Haben Sie weitere Fragen zu unserem Beispiel für maschinelles Lernen? Wir helfen gerne weiter!
JETZT TERMIN FÜR EIN PERSÖNLICHES GESPRÄCH VEREINBAREN
Kostenloses eBook zum gratis Download: Predictive Analytics – Was es ist und wie Sie beginnen können
Predictive Analytics: Methoden, Daten und Ideen aus der Praxis
Downloaden Sie jetzt das kostenlose eBook.
Wohin dürfen wir das PDF senden?


- Wir verwenden diese Daten nur zur Beantwortung Ihre Anfrage. Hier können Sie unsere Datenschutzerklärung finden.
